Built on Scar Tissue - Part 1: The QA Job Nobody Built AI For
Why experience can’t be generated - and why that matters more than ever
"It takes considerable knowledge just to realize the extent of your own ignorance."
- Thomas Sowell
The most dangerous test suite isn’t an empty one
Fifteen years across fintech, regulated digital health, and enterprise platforms teaches you things that no tool documents and which no training covers.
One of them is this: an empty test suite is never the real problem.
Everyone can see an empty suite. It signals incompleteness loudly. Someone asks questions. Someone pushes back. The release slows down. The absence of coverage is visible - and visibility, even uncomfortable visibility, triggers the right conversation.
The dangerous suite is the one that looks complete.
For a product that we worked on, there were 30 well-written cases with happy path covered, error states handled, role visibility checked. The test cases were structured, readable, and confidently produced. That suite got signed off. It built confidence in a room full of people who should still be asking questions. And then a customer in production found what the suite didn’t - quietly, expensively, sometimes irreversibly.
I’ve watched this happen across domains. In fintech, where a silent backend failure didn’t throw an error - it just quietly processed the wrong amount. In digital health, where a reading got confirmed as saved but never actually reached the server. In both cases, the test suite was thorough, but the thinking behind it wasn’t. We don’t have a writing problem. We have a thinking problem.
When AI-driven test generation arrived, I wasn’t excited. I was concerned.
The problem with convincing output
I have been concerned not because AI produces bad test cases, but because it produces convincing ones. LLM-based generation is extraordinarily good at one thing - pattern completion. Feed it a feature description, it returns structured cases: valid inputs, error states, happy path, sad path, all correctly labelled. These test cases look exactly like what a complete suite is supposed to look like.
That appearance of completeness is precisely the risk.
Because what's missing isn't visible. It never is.
One example of what doesn’t get generated: the question of whether the API enforces what the UI restricts. The scenario where a user double-taps submit and the backend processes the request twice. The case where a confirmation message fires and nothing persists to the database. The role that the UI blocks but the API doesn’t.
These gaps don’t come from pattern-matching against training data. They come from having seen these failures before - in real systems, under real delivery pressure, with real consequences. That knowledge lives in people who’ve spent years watching where software actually breaks. It doesn’t live in a generation model and it can’t be retrieved by prompting more carefully.
Melissa Reeve, author of Hyperadaptive, named the broader shift on TechLead Journal (Ep. 254): jobs are moving from doing tasks to evaluating the output of AI. Human as evaluator. In QA specifically, that evaluation is not a soft skill. It is the entire discipline - and it was the part nobody was building for.
A blank suite tells you something is missing. A complete-looking suite with gaps tells you nothing - until production does.
What years of QA actually teaches you
The gaps that cause production incidents are not random. They repeat. Across teams, across domains, across levels of QA maturity - the same categories of missing thinking appear with uncomfortable consistency.
This repeatability matters. These gaps are not a function of individual carelessness. They are a function of how systems get built under delivery pressure - and of what never makes it into a specification because nobody thought to question it.
Some examples of such gaps are:
- Authorization mismatches. The UI correctly restricts an action for a given role. The API does not enforce the same restriction. The test suite validates UI behaviour and concludes the access control is working. The backend exposure goes completely untested - invisible behind an interface that looks correct.
- Idempotency gaps. Double submission, network retries, page refresh after a form submit - these are normal user and network behaviours. They are almost never in generated test suites. The implicit assumption is that a user performs one action and waits. Real users and real networks do not behave that way.
- Silent backend failures. The UI shows a success confirmation. Behind it, a validation error, a timeout, or a write failure occurred and did not surface. The user proceeds believing the action completed. The record does not exist. This pattern is particularly dangerous in healthcare and fintech domains where the absence of a record is not neutral.
- State consistency issues. Partial saves, stale sessions, cached data, race conditions under concurrent access. These failures are invisible at unit level and only surface under integrated, stateful testing.
- Audit trail gaps. In regulated systems, certain actions must be logged, attributed, and traceable. Generated suites cover whether an action succeeds. They rarely ask whether the audit record was created, attributed correctly, or would survive a rollback.
- Dependency failure paths. Third-party services time out. APIs return partial responses. External systems degrade. How a system behaves when its dependencies fail partially - not completely - is a category of scenario that almost never appears in generated output.
None of these are exotic. They sit at the boundary between what gets specified and what gets questioned. A generation model produces the former. The latter requires someone who has watched what happens when these questions go unasked.
One example that stays with me
This was a heart rate and SpO2 capture workflow - the kind you’d expect from a health wearable syncing into a medical app. There were around 30 test cases, carefully written: valid readings, sensor failure states, sync success, history screen, permissions, error handling. It looked complete.
What was missing
No test for double submission. A user taps "Save" twice, or the network retries during sync. The UI confirms success both times. The same reading gets stored twice. Now the health trend graph shows a spike that was never real.
No test for API-level access control. The UI correctly hid detailed health records from a restricted account (eg other family member account). But the backend API still returned full history when called directly. This was a privacy and compliance risk - invisible behind a UI that looked correct.
No test for silent backend failure. The app showed "Saved successfully." The user moved on. But the record never reached the server, and the health history stayed incomplete.
A doctor may never see a real spike that should trigger attention. Or worse - may get alerted about spikes that were never real, because duplicate records made the trend look abnormal. The suite looked done. The thinking behind it wasn't.
Generation is a pattern. Review is a philosophy.
These are two structurally different jobs. Most teams collapse them into one - and that collapse is where the blind spot lives.
Generation writes the cases. It fills the structure, covers the visible paths, produces output that matches the shape of a complete suite. AI is genuinely good at this. Use it.
Review questions the cases. It steps back and asks: what is this suite assuming? What breaks if the real user doesn’t behave like the test imagined? What failure mode is normal for this kind of system that nobody represented here?
That is adversarial thinking. It does not emerge from training data.
It emerges from scar tissue.
The real risk in AI-assisted QA is not that generation produces wrong output. It is that good-looking output reduces the scrutiny that would have caught what it missed. A suite that appears exhaustive makes people feel safe. And that feeling - the false confidence of a full-looking suite - is the most expensive thing AI has introduced into the quality process.
Speed was never the problem in QA. Scrutiny was.
What I started building in my career break
We started shipping AI from 2023. In mid 2024, during a career break, I started building something for this gap - not a generator, but a reviewer. A tool that does what a senior QA lead does in a review: reasons about intent, surfaces gaps, flags what is redundant, and gives a structured verdict. Not a score. A reasoned call with specifics.
A few fellow professionals have been generous enough to run it on real suites and come back with honest feedback on where it falls short. That loop has shaped it more than anything else.

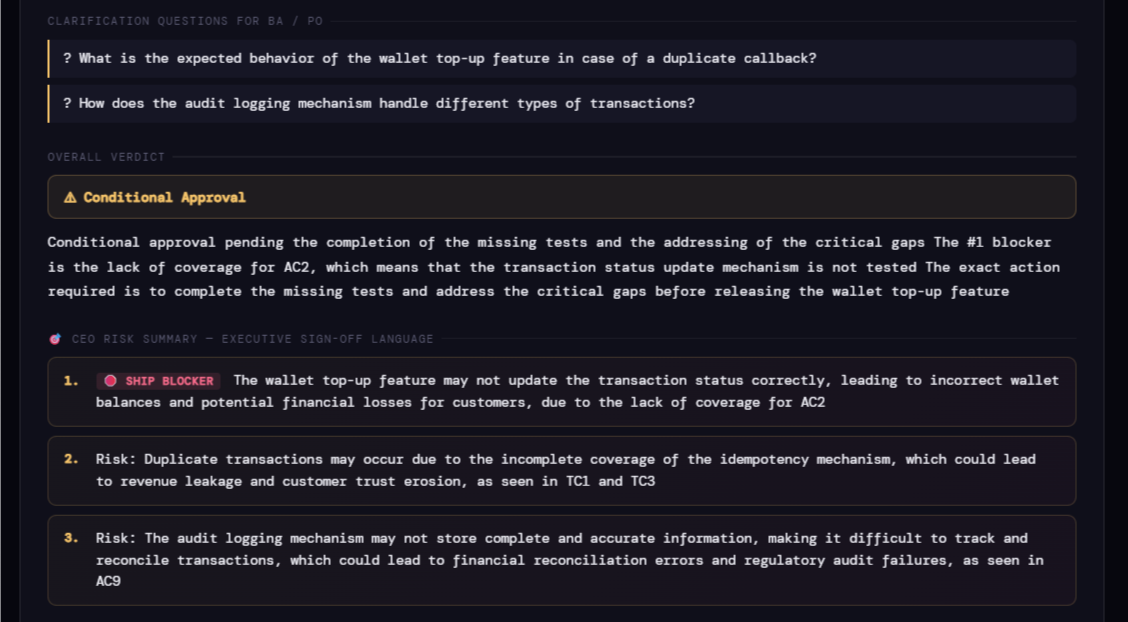
The agent doesn’t sign off releases. It prevents humans from signing off blindly. It doesn’t make QA faster. It makes the thinking harder to skip.
Part 2 covers what the agent does, what it catches consistently across suites, and what building it has taught me about encoding fifteen years of QA instinct into something that scales.
Coming soon. Stay tuned.